One Billion Row Challenge in Golang - From 95s to 1.96s
Introduction
The One Billion Row Challenge (1BRC) is quite simple: the task is developing a program capable of read a file with 1 billion lines, aggregating the information contained in each line, and print a report with the result. Each line within the file contains a weather station name and a temperature reading in the format <station name>;<temperature>, where station name may have spaces and other special characters excluding ;, and the temperature is a floating-point number ranging from -99.9 to 99.9 with precision limited to one decimal point. The expected output format is {<station name>=<min>/<mean/<max>, ...}, sorted alphabetically by station name, and where min, mean and max denote the computed minimum, average and maximum temperature readings for each respective station.
Example of a measurement file:
Yellowknife;16.0
Entebbe;32.9
Porto;24.4
Vilnius;12.4
Fresno;7.9
Maun;17.5
Panama City;39.5
...Example of the expected output:
{Abha=-23.0/18.0/59.2, Abidjan=-16.2/26.0/67.3, Abéché=-10.0/29.4/69.0, ...}Given that 1-billion-line-file is approximately 13GB, instead of providing a fixed database, the official repository offers a script to generate synthetic data with random readings. Just follow the instructions to create your own database.
Although the challenge is primarily targeted for Java developers, the problem presets an interesting toy exercise to experiment in any language. As I’ve been working with Golang in a daily-basis at Gamers Club, I decided to give it a try to test how deep I could go. But before going forward with this article, I want to acknowledge that, despite being well-versed, I am no specialist in Golang and I’m kind of dumb for low level optimizations - a domain to which I have never been very interested.
In this article I will present all the steps I took to optimize the solution. Everything was written and tested in a Ryzen 9 7900X PC (not overclocked, so 4.7HGz) with 12 cores and 24 threads, a ASRock B650M-HDC/M.2 motherboard, 2x16GB 6000mhz DDR5 Kingston Fury Beast RAM (also not overclocked and no EXPO enabled), and a Kingston SSD SV300S37A/120G. Windows 11 with Go 1.22.0 AMD64.
The partial results I present is the lowest consistent value I got from the runs while the editor and browser were open. The final result is presented by presenting the aggregated result from 55 executions.
How Slow is Too Slow?
Before deciding to work seriously on this challenge, I was curious on how much slow is reading and processing the scary 1 billion rows file. I had a feeling that a naïve approach to it would take a long time. Driven by this curiosity, I wanted to give it a try and implement the simplest solution possible:
type StationData struct {
Name string
Min float64
Max float64
Sum float64
Count int
}
func run() {
data := make(map[string]*StationData)
file, err := os.Open("measurements.txt")
if err != nil {
panic(err)
}
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
line := scanner.Text()
parts := strings.Split(line, ";")
name := parts[0]
tempStr := strings.Trim(parts[1], "\n")
temperature, err := strconv.ParseFloat(tempStr, 64)
if err != nil {
panic(err)
}
station, ok := data[name]
if !ok {
data[name] = &StationData{name, temperature, temperature, temperature, 1}
} else {
if temperature < station.Min {
station.Min = temperature
}
if temperature > station.Max {
station.Max = temperature
}
station.Sum += temperature
station.Count++
}
}
printResult(data)
}
func printResult(data map[string]*StationData) {
result := make(map[string]*StationData, len(data))
keys := make([]string, 0, len(data))
for _, v := range data {
keys = append(keys, v.Name)
result[v.Name] = v
}
sort.Strings(keys)
print("{")
for _, k := range keys {
v := result[k]
fmt.Printf("%s=%.1f/%.1f/%.1f, ", k, v.Min, v.Sum/float64(v.Count), v.Max)
}
print("}\n")
}
func main() {
started := time.Now()
run()
fmt.Printf("%0.6f", time.Since(started).Seconds())
}To my surprise, the code above ran in ~95 seconds, a lot better than I expected it would be.
Note that printResult and main functions will be used for the remaining of the article with little to no change.
How Fast is Possible?
Satisfied, I went to bed but I couldn’t sleep. I knew how much time I needed to process the data, but I couldn’t stop asking what would be the fastest time possible to just open and read the file, without the overhead of processing it.
Basic Scanner
func run() {
file, err := os.Open("measurements.txt")
if err != nil {
panic(err)
}
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
scanner.Bytes()
}
if err := scanner.Err(); err != nil {
panic(err)
}
}First try. Notice that I’m using Bytes() instead of String(), a quick research told me that String() conversion is slower and involves allocation of memory. The Bytes() function reuse an internal buffer, returning the same object so there is no additional allocation. The result was astonishing 36 seconds.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
Scanner Buffer
Scanner default configuration is really bad for this task. I already knew that it was possible to read much faster, since the Java entries could reach result time as fast as 1.5s. But 36s seconds was surprisingly slow.
The scanner class has a Buffer function, which accepts a predefined []byte object and a maximum number of elements for the case when the buffer can grow up in size. Without much details about how it works internally, I tried to use it and tested some different values for the BUFFER_SIZE:
scanner.Buffer(make([]byte, BUFFER_SIZE), BUFFER_SIZE)| Buffer Size | Time (in seconds) |
|---|---|
1024 | 27.4543000 |
64*64 | 12.6580670 |
128*128 | 8.2336520 |
256*256 | 7.0902360 |
512*512 | 6.9288370 |
1024*1024 | 6.7667700 |
2048*2048 | 6.7406200 |
4096*4096 | 6.7061090 |
8192*8192 | 7.0757130 |
Much better! So, using a buffer around 2048x2048 and 4096x4096 bytes (~4MB and ~16MB, respectively) could improve 80%, reaching around 6.7 seconds.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
Bufio Reader
Another quick test I could do was using the bufio.Reader object, which reads byte-by-byte:
reader := bufio.NewReader(file)
for {
_, err := reader.ReadByte()
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
}This change actually increased the time to 25.508648 seconds.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
| Bufio Reader | 25.508648 |
Bufio Reader Line
Instead of reader.ReadByte(), I tried reader.ReadLine, which reduced the time to 12.632035 seconds, but still slower than scanner.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
| Bufio Reader | 25.508648 |
| Bufio Reader (by line) | 12.632035 |
File Read
After the initial exploration, I checked how Scanner.Scan works internally and noticed that it does a lot of things that I don’t need. It manipulates the buffer object a lot, not sure why. I also found that it uses file.Read, which I never used before. Let’s try it:
buffer := make([]byte, 1024)
for {
_, err := file.Read(buffer)
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
}Resulting in 18.867314 seconds.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
| Bufio Reader | 25.508648 |
| Bufio Reader (by line) | 12.632035 |
| File Read | 18.867314 |
File Read Buffer
Notice that File.Read accepts a buffer. When we configure the buffer in the Scanner object, internally, scanner uses this buffer to read from file. So I tested different buffer sizes again:
| Buffer Size | Time (in seconds) |
|---|---|
128*128 | 2.612572 |
256*256 | 1.394397 |
512*512 | 1.189664 |
1024*1024 | 1.008404 |
2048*2048 | 0.984717 |
4096*4096 | 1.045845 |
8192*8192 | 1.321442 |
Great! Now that make a lot more sense. 0.984717 seconds using 2048x2048 (~4MB) seems a great choice for buffer reading.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
| Bufio Reader | 25.508648 |
| Bufio Reader (by line) | 12.632035 |
| File Read | 18.867314 |
| File Read Buffer | 0.984717 |
I lack the knowledge to explain why large-buffer file.Read is so much better than other versions, but I believe it may be related to how the information is retrieved from SSD.
With Communication
To finish up the minimum structure, I wanted to communicate with multiple goroutines to get a feel for how much overhead that could add. My idea was to create a single goroutine and send the buffer directly into it using a channel, so I can measure the cost of communication alone.
func consumer(channel chan []byte) {
for {
<-channel
}
}
func run() {
channel := make(chan []byte, 10)
go consumer(channel)
file, err := os.Open("measurements.txt")
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
buffer := make([]byte, BUFFER_SIZE)
for {
_, err := file.Read(buffer)
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
channel <- buffer
}
}This increased the time to 1.266833 seconds.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
| Bufio Reader | 25.508648 |
| Bufio Reader (by line) | 12.632035 |
| File Read | 18.867314 |
| File Read Buffer | 0.984717 |
| Single goroutine | 1.266833 |
Copying Buffer
I still got some problems. The first one is that the File.Read(buffer) will override the buffer every reading, thus, if we send the buffer to the channel directly, among other synchronization problems, the consumer will read inconsistent data. This problem will be even worse once we add more goroutines.
To avoid this situation, I will copy the buffer data into another array:
data := make([]byte, n)
copy(data, buffer[:n])
channel <- dataIncreasing the time to about 2.306197 seconds, almost doubling it. Notice that I tried to create the slice and copy the data manually with for _, b in := range buffer, but without any improvement.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
| Bufio Reader | 25.508648 |
| Bufio Reader (by line) | 12.632035 |
| File Read | 18.867314 |
| File Read Buffer | 0.984717 |
| Single goroutine | 1.266833 |
| Copying Buffer | 2.306197 |
Leftover Logic
A natural way to scale our solution is sending each chunk of data to different goroutine running in parallel. The goroutines aggregate the data independently and when finished, the main thread should merge the information. I believe that this process is similar to how some NoSQL databases optimize their queries.
However, at this point, the main thread reads a fixed buffer amount from the file but the lines can have different lengths, which means that the buffer will cut the last line unless we’re really lucky.
I added a “leftover logic” to store the incomplete last line from one reading to be used as the first part of the next chunk.
readBuffer := make([]byte, BUFFER_SIZE)
leftoverBuffer := make([]byte, 1024)
leftoverSize := 0
for {
n, err := file.Read(readBuffer)
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
// Find the last '\n' (byte=10)
m := 0
for i := n - 1; i >= 0; i-- {
if readBuffer[i] == 10 {
m = i
break
}
}
data := make([]byte, m+leftoverSize)
copy(data, leftoverBuffer[:leftoverSize])
copy(data[leftoverSize:], readBuffer[:m])
copy(leftoverBuffer, readBuffer[m+1:n])
leftoverSize = n - m - 1
channel <- data
}Resulting in 2.359820 seconds.
| Experiment | Time (in seconds) |
|---|---|
| Basic Scanner | 36.114680 |
| Scanner Buffer | 6.706109 |
| Bufio Reader | 25.508648 |
| Bufio Reader (by line) | 12.632035 |
| File Read | 18.867314 |
| File Read Buffer | 0.984717 |
| Single goroutine | 1.266833 |
| Copying Buffer | 2.306197 |
| Leftover Logic | 2.359820 |
Workers and Communication
As stated previously, the natural evolution from here is to create a workflow where goroutines process the data chunks and return the partial aggregation and the main thread merge and present the result.
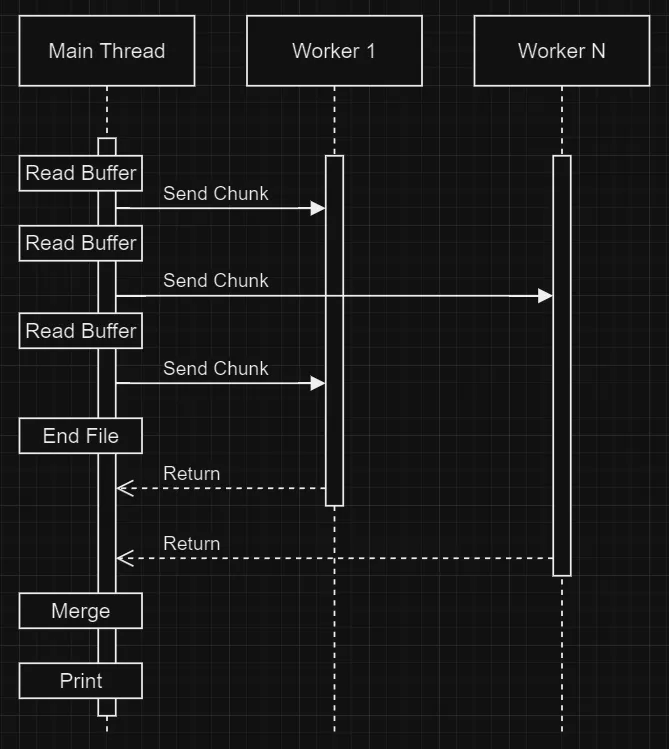
My idea was creating a list of goroutines and sending data to each of them sequentially, cycling the goroutines until the end of the file. There were no significant increase of time with this modification. At this point, I just copied the old processing with few changes to consumer:
func consumer(input chan []byte, output chan map[string]*StationData, wg *sync.WaitGroup) {
defer wg.Done()
data := make(map[string]*StationData)
separator := []byte{';'}
for reading := range input {
scanner := bufio.NewScanner(bytes.NewReader(reading))
for scanner.Scan() {
// Processing using bytes instead of string
line := scanner.Bytes()
parts := bytes.Split(line, separator)
if len(parts) != 2 {
fmt.Println("Invalid line: ", string(line))
continue
}
name := string(parts[0])
temperature, err := strconv.ParseFloat(string(parts[1]), 64)
if err != nil {
fmt.Println(err)
return
}
station, ok := data[name]
if !ok {
data[name] = &StationData{name, temperature, temperature, temperature, 1}
} else {
if temperature < station.Min {
station.Min = temperature
}
if temperature > station.Max {
station.Max = temperature
}
station.Sum += temperature
station.Count++
}
}
}
output <- data
}
func run() {
inputChannels := make([]chan []byte, N_WORKERS)
outputChannels := make([]chan map[string]*StationData, N_WORKERS)
var wg sync.WaitGroup
wg.Add(N_WORKERS)
// Create workers
for i := 0; i < N_WORKERS; i++ {
input := make(chan []byte, CHANNEL_BUFFER)
output := make(chan map[string]*StationData, 1)
go consumer(input, output, &wg)
inputChannels[i] = input
outputChannels[i] = output
}
file, err := os.Open("measurements.txt")
if err != nil {
panic(err)
}
defer file.Close()
readBuffer := make([]byte, READ_BUFFER_SIZE)
leftoverBuffer := make([]byte, 1024)
leftoverSize := 0
currentWorker := 0
for {
n, err := file.Read(readBuffer)
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
m := 0
for i := n - 1; i >= 0; i-- {
if readBuffer[i] == 10 {
m = i
break
}
}
data := make([]byte, m+leftoverSize)
copy(data, leftoverBuffer[:leftoverSize])
copy(data[leftoverSize:], readBuffer[:m])
copy(leftoverBuffer, readBuffer[m+1:n])
leftoverSize = n - m - 1
inputChannels[currentWorker] <- data
currentWorker++
if currentWorker >= N_WORKERS {
currentWorker = 0
}
}
// Closes the input channels, making the workers to leave their processing loop
for i := 0; i < N_WORKERS; i++ {
close(inputChannels[i])
}
// Wait for all workers to finish processing
wg.Wait()
for i := 0; i < N_WORKERS; i++ {
close(outputChannels[i])
}
// Aggregates the results
data := make(map[string]*StationData)
for i := 0; i < N_WORKERS; i++ {
for station, stationData := range <-outputChannels[i] {
if _, ok := data[station]; !ok {
data[station] = stationData
} else {
if stationData.Min < data[station].Min {
data[station].Min = stationData.Min
}
if stationData.Max > data[station].Max {
data[station].Max = stationData.Max
}
data[station].Sum += stationData.Sum
data[station].Count += stationData.Count
}
}
}
}
Now we gotta 2 new parameters to adjust: the number of workers (N_WORKERS) and the size of channel buffer (CHANNEL_BUFFER). To discover the impact of these parameters, I created a grid test that run with each pair of configuration, you can see the results in the table below.
| Workers\ Buffer | 1 | 10 | 15 | 25 | 50 | 100 |
|---|---|---|---|---|---|---|
| 5 | 21.33 | 20.74 | 20.41 | 20.29 | 19.51 | 20.13 |
| 10 | 13.36 | 11.25 | 11.87 | 11.08 | 11.86 | 11.93 |
| 15 | 11.25 | 9.6 | 9.63 | 8.9 | 9.13 | 12.27 |
| 25 | 11.59 | 8.25 | 8.35 | 8.31 | 8.33 | 8.27 |
| 50 | 9.88 | 8.51 | 8.41 | 8.42 | 8.28 | 8.01 |
| 100 | 9.38 | 8.54 | 8.30 | 8.54 | 8.29 | 8.56 |
As expected, few goroutines with a single message buffer in the channel lock the main thread, waiting the channel to become available. There was no significant gain with more than 25 workers after a buffer sized of 10. For a balanced setting, I will proceed with 25 workers and buffer size of 25.
Optimizations
Starting from the basic implementation, I will show how I identified and worked to optimize individual code paths. If you wish to repeat the process, you can just add the following snippet at the beginning of you program:
f, err := os.Create("cpu_profile.prof")
if err != nil {
panic(err)
}
defer f.Close()
if err := pprof.StartCPUProfile(f); err != nil {
panic(err)
}
defer pprof.StopCPUProfile()and then run go tool pprof -http 127.0.0.1:8080 cpu_profile.prof, which will open a detailed site showing CPU profiling insights. The image below is one of the reports presented by this site, called flame graph. Here we can see the worst offenders in my code: bytes.Split, strconv.ParseFloat, slicebytetostring, and mapaccess2_faststr:
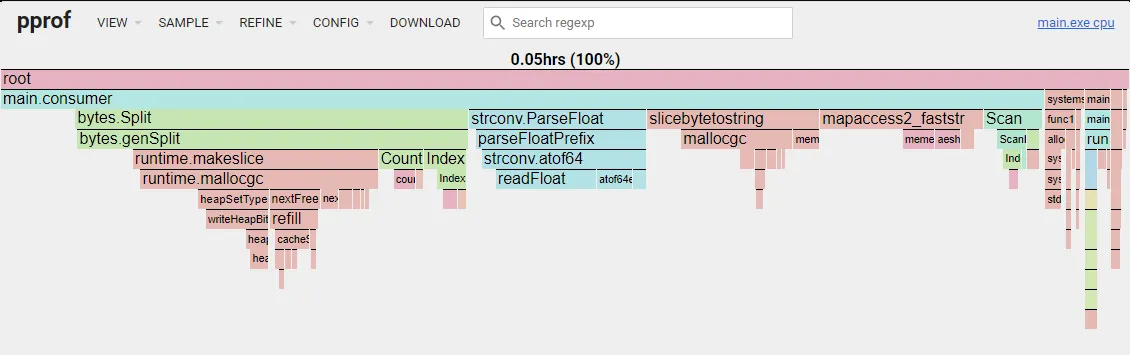
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
Custom Bytes Split
Let’s begin with the bytes.Split() function, which I’m using to split the name and the temperature readings for each line. We can see in the flame graph that most of the time consumed is attributed to memory allocations (runtime.makeslice and runtime.mallocgc). The simplest solution is keeping a fixed slice buffer for name and temperature and copy the bytes from the original line to the new buffers:
func consumer(input chan []byte, output chan map[string]*StationData, wg *sync.WaitGroup) {
defer wg.Done()
data := make(map[string]*StationData)
nameBuffer := make([]byte, 100)
temperatureBuffer := make([]byte, 50)
for reading := range input {
scanner := bufio.NewScanner(bytes.NewReader(reading))
for scanner.Scan() {
line := scanner.Bytes()
nameSize, tempSize := parseLine(line, nameBuffer, temperatureBuffer)
name := string(nameBuffer[:nameSize])
temperature, err := strconv.ParseFloat(string(temperatureBuffer[:tempSize]), 64)
...
func parseLine(line, nameBuffer, temperatureBuffer []byte) (nameSize, tempSize int) {
i, j := 0, 0
for line[i] != 59 { // stops at 59, which is the ASCII code for;
nameBuffer[j] = line[i]
i++
j++
}
i++ // skip ;
k := 0
for i < len(line) && line[i] != 10 { // stops at 10, which is the ASCII code for \n
temperatureBuffer[k] = line[i]
i++
k++
}
return j, k
}With this change only, we could reach 5.526411 seconds.
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
The new flame graph looks like this:
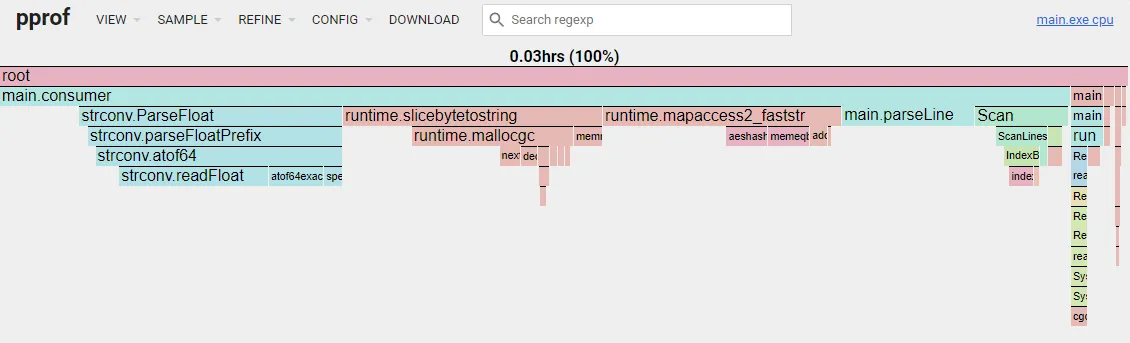
Custom Byte Hash
Now, the next major offender is the bytes-to-string conversion (for the name) and the subsequent map lookup. The former is a problem because the statement string(nameBuffer[:nameSize]) also allocates memory. Luckily, this conversion is not necessary in interaction of the loop.
The name as string serves two purposes: first, to store it in the StationData struct, and second, to be used for the lookup in the map. The map lookup involves extracting a hash from the key and apply internal logic to locate the corresponding data within the struct. We can speed up this process by sending a pre-hashed key.
I decided to use FNV hash, which is a builtin in Go. I’ve no idea of how it works, but it works:
hash := fnv.New64a() // Create a new FNV hash
nameBuffer := make([]byte, 100)
temperatureBuffer := make([]byte, 50)
for reading := range input {
scanner := bufio.NewScanner(bytes.NewReader(reading))
for scanner.Scan() {
line := scanner.Bytes()
nameSize, tempSize := parseLine(line, nameBuffer, temperatureBuffer)
// Note that we removed the string convertion here
name := nameBuffer[:nameSize]
temperature, err := strconv.ParseFloat(string(temperatureBuffer[:tempSize]), 64)
if err != nil {
panic(err)
}
hash.Reset()
hash.Write(name)
id := hash.Sum64() // Compute the data key here, generating a uint64
station, ok := data[id]
if !ok {
data[id] = &StationData{strign(name), temperature, temperature, temperature, 1}
} else {
...Another significant improvement: 4.237007 seconds.
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
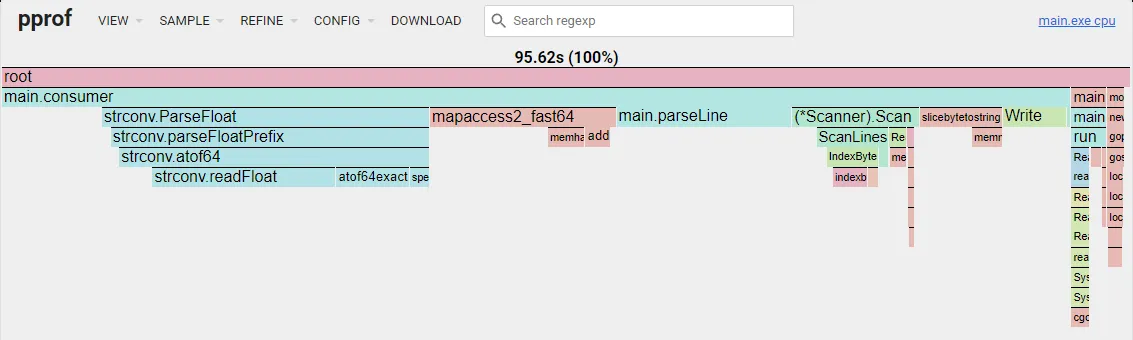
The image below shows the new flame graph. Notice that the slicebytetostring was severely reduced and mapaccess2_faststr was changed to mapacess2_fast64.
Parsing Float
The next big offender is strconv.ParseFloat. I tried the same approach of converting the bytes to float directly:
// Attempt 1:
var temperature float64
binary.Read(bytes.NewReader(temperatureBuffer[:k]), binary.BigEndian, &temperature)
// Attemp 2:
temperature, err := bytesconv.ParseFloat(temperatureBuffer[:k], 64)The first attempt was using the binary builtin package. But its performance was a lot worse. The second attempt was using the bytesconv package from perf package, as you can see here, but the result was equivalent. I also considered parsing the individual bytes, but I couldn’t thought in any real improvement to the current function.
However, at this point, I had already consulted some of the Java solutions and one of the best approaches they use is converting the temperature to int instead of float, which proved to be a lot more efficient. Simply using:
temperature, err := strconv.ParseInt(string(temperatureBuffer[:tempSize]), 10, 64)already showed some improvements. But notice that, if we just convert the data to int from the string, we’ll lose the decimal point. Thus, I wrote a custom int conversion that will keep the decimal point and generate an int equivalent to int(float64(temperature_string)*10). We can adjust the final result dividing min, mean and max by 10.
func bytesToInt(byteArray []byte) int {
var result int
negative := false
for _, b := range byteArray {
if b == 45 { // 45 = `-` signal
negative = true
continue
}
// For each new number, move the old number one digit to the left.
result = result*10 + int(b-48) // 48 = '0', 49 = '1', ...
}
if negative {
return -result
}
return result
}
temperature := bytesToInt(temperatureBuffer[:tempSize])Again another large improvement: 3.079632 seconds.
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
Notice that in the new flame graph, we can see the Scanner.Scan becoming a relevant part now.
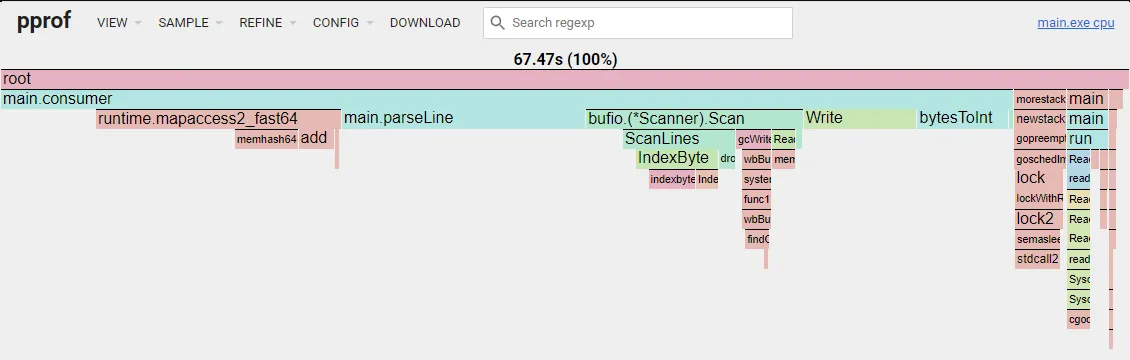
Custom Scan
The custom scan function is very straightforward, we just read the bytes until we find a \n. I altered the parseLine to include this logic:
for reading := range input {
readingIndex := 0
for readingIndex < len(reading) {
next, nameSize, tempSize := nextLine(readingIndex, reading, nameBuffer, temperatureBuffer)
readingIndex = next
name := nameBuffer[:nameSize]
temperature := bytesToInt(temperatureBuffer[:tempSize])
...
func nextLine(readingIndex int, reading, nameBuffer, temperatureBuffer []byte) (nexReadingIndex, nameSize, tempSize int) {
i := readingIndex
j := 0
for reading[i] != 59 { // ;
nameBuffer[j] = reading[i]
i++
j++
}
i++ // skip ;
k := 0
for i < len(reading) && reading[i] != 10 { // \n
if reading[i] == 46 { // .
i++
continue
}
temperatureBuffer[k] = reading[i]
i++
k++
}
readingIndex = i + 1
return readingIndex, j, k
}Putting us at 2.825991 seconds
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
As usual, the next flame graph:
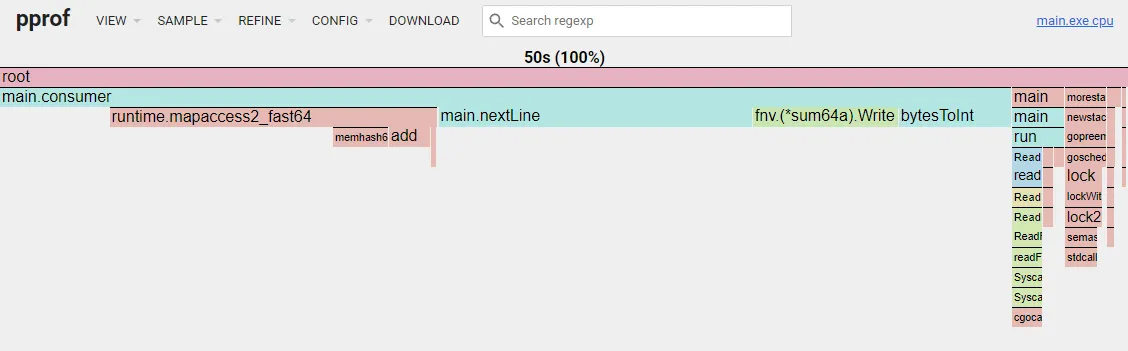
Custom Hash
I began considering a custom computation of the map hash after noticing the increasing relevance of fnv.(*sum64a).Write. At this point, I had done some analysis and could extract some insights about the data in the measurements file. One interesting finding was determining the number of bytes required to represent a station name without colliding with other stations. In my database, I found that I need 9 bytes, with values ranging from 65 to ~196.
Using this information, I had the idea of concatenating every number into a single large uint64 while ensuring the value doesn’t surpass the upper limit of 18446744073709551615:
func hash(name []byte) uint64 {
n := min(len(name), 10) // 10 bytes, one more than we need just to be safe
var result uint64
for _, b := range name[:n] {
v := b - 65
var m uint64 = 10
if v >= 10 {
m = 100
} else if v >= 100 {
m = 1000
}
result = result*m | uint64(b)
}
return result
}Before implementing it in my solution I benched against the fnv hash, running these functions over 410 names iterating 10000 times:
- FNV Hash: 0.073704 seconds
- Our Hash: 0.009771 seconds
It’s worthing noting that this hash is very situational and may fail in a different datasets, a problem for later. Nonetheless, in this particular case, the result was 2.717442 seconds.
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
| Custom Hash | 2.717442 |
The new flame graph:
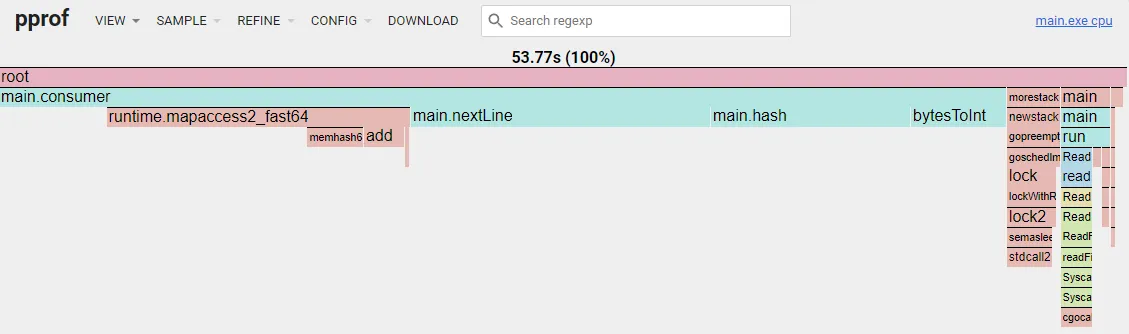
Swiss Map
Time to deal with the large elephant in the room, the runtime.mapaccess2_fast64 map lookup. Despite spending some hours of research, I couldn’t found any viable way to optimize the builtin map. However, there is a community alternative called Swiss Map, which sells itself as faster and more memory efficient than the builtin one. Replacing it is almost a drop-in, with just some syntax changes:
data := swiss.NewMap[uint64, *StationData](1024) // important the initial value to be high
...
station, ok := data.Get(id)
if !ok {
data.Put(id, &StationData{string(name), temperature, temperature, temperature, 1})
} else {
...With swiss map, not only I could reduce a bit the minimum time to 2.677549 seconds but the time was more consistently near to 2.7.
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
| Custom Hash | 2.717442 |
| Swiss Map | 2.677549 |
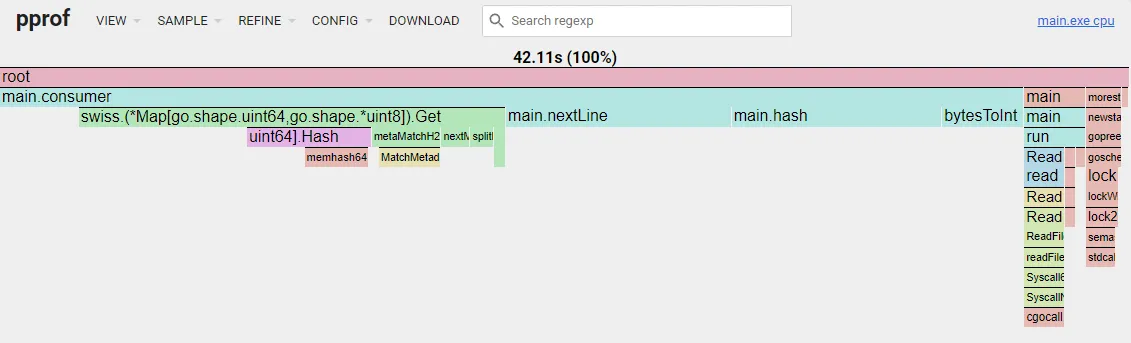
Simpler Hash Function
Revisiting the hash function, I found this algorithm online, which looked like a simpler hash than mine:
func hash(name []byte) uint64 {
var h uint64 = 5381
for _, b := range name {
h = (h << 5) + h + uint64(b)
}
return h
}Repeating the same tests I did before:
- FNV Hash: 0.073704 seconds
- Previous: 0.009771 seconds
- DJB2: 0.002003 seconds
Almost 5x better. With this new version I could further reduce the time to 2.588396 seconds.
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
| Custom Hash | 2.717442 |
| Swiss Map | 2.677549 |
| DJB2 Hash | 2.588396 |
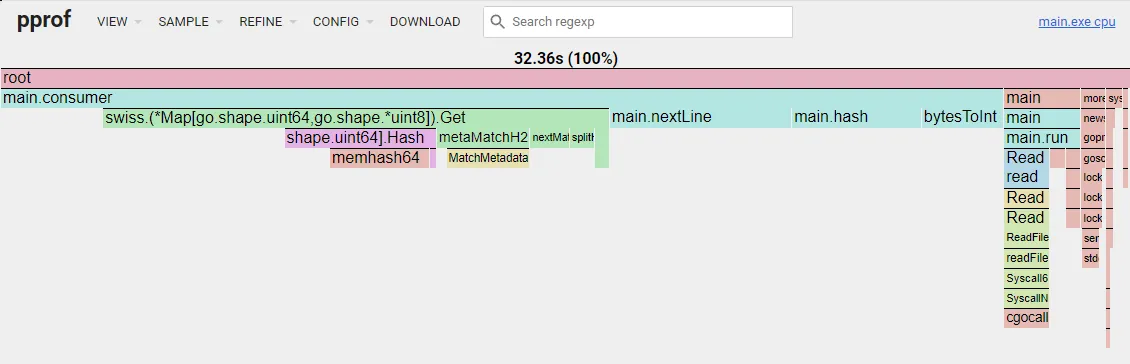
Inline Functions
The consumer is the hot path, thus, any function call inside of it can potentially generate an unnecessary overhead. However, inlining all the functions didn’t shown any improvement, but made me lose the profiling information.
EDIT 2024-03-18: I just learned that Go inline functions automatically whenever possible. If you don’t want this behavior you can disable it by add //go:noinline to the functions:
//go:noinline
func sum(a, b int) int {
return a + b
}Workers Reading The File
While drafting this article, I realized that I was super close to reaching the minimum threshold I had set with the main thread configuration. Upon analyzing that most of the time in the main thread was related to goroutine communication - with 0.98s to reading the file and 1.306s to communicating the data to goroutines - it struck me that I could move the file reference to the consumer and completely eliminate the communication overhead, including replacing the communication buffer for a fixed buffer, reducing the memory allocation overhead.
readBuffer := make([]byte, READ_BUFFER_SIZE)
for {
lock.Lock()
n, err := file.Read(readBuffer)
lock.Unlock()
...
}By delegating the reading task to the consumer, the goroutine can locally read from the file using a mutex to avoid any concurrency issues. For testing purpose only, I will discard the first and the last line of the buffer to avoid the complex distributed leftover logic for now. The results were further reduced to 2.108564 seconds!
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
| Custom Hash | 2.717442 |
| Swiss Map | 2.677549 |
| DJB2 Hash | 2.588396 |
| Worker Reading | 2.108564 (Invalid Output) |
Trash Bin
In order to recover the first and last line of each chunk, I created a Trash Bin goroutine, that receives the discarded parts from other goroutines and try to merge the individual bytes in complete lines:
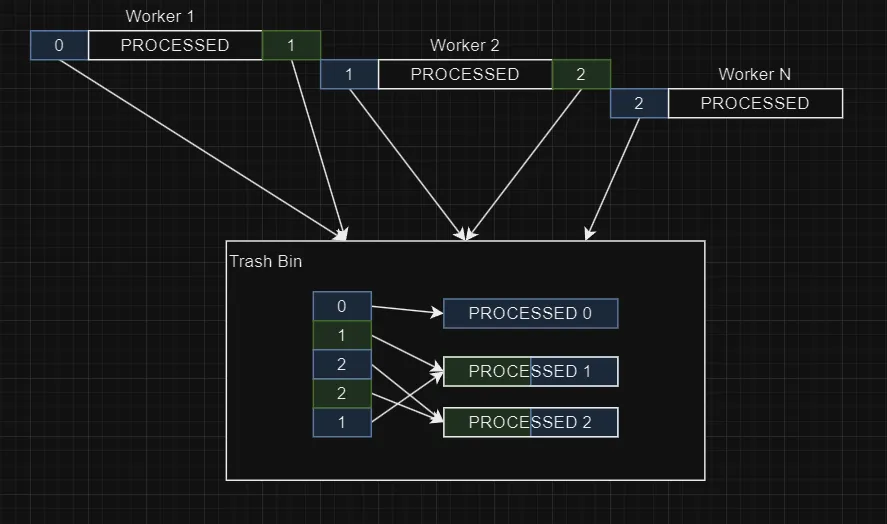
Notice that the first line of the first goroutine is always a complete valid line, and the last line of the last goroutine is always empty (the file ends with \n). All parts between are matched by their id. Each read from file increases the id, the first line is kept as the previous id and the last line assumes the next id. This process is controlled by the same mutex used in reading the file, guaranteeing the concurrency consistency. The trash bin merge the parts considering that they may be the initial bytes of the block (green) or the final bytes of the block (blue). All together and our time is 2.107401 seconds
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
| Custom Hash | 2.717442 |
| Swiss Map | 2.677549 |
| DJB2 Hash | 2.588396 |
| Worker Reading | 2.107401 |
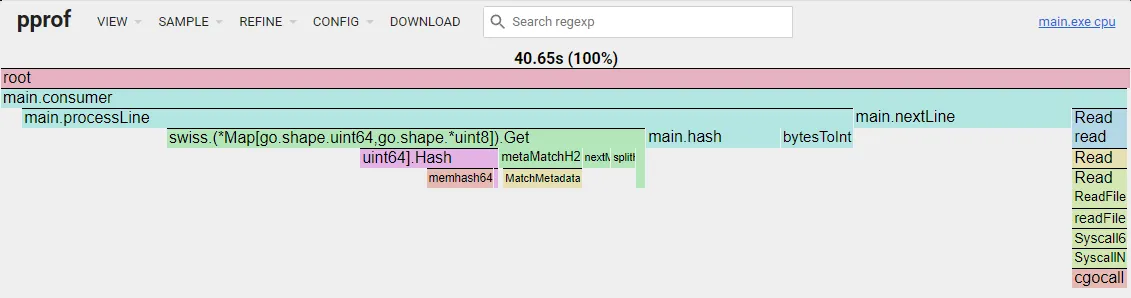
Name and Temp Buffer
I finally realized that I don’t need a name and temperature buffer. If I just use a sub-slice of the read buffer, I don’t need to copy the name and temperature bytes over and over. With this change I could further reduce the time to 2.070337 seconds!
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
| Custom Hash | 2.717442 |
| Swiss Map | 2.677549 |
| DJB2 Hash | 2.588396 |
| No Name and Temp Buffers | 2.070337 |
The final flame graph:
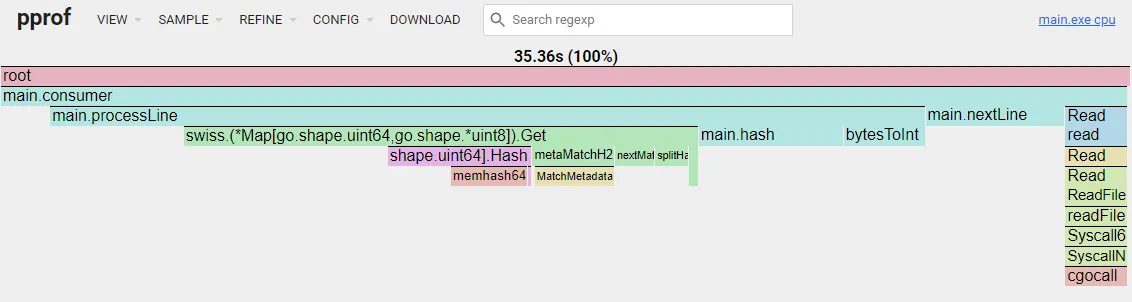
Finishing Up With Grid Test
To finish up in style, I wanted to perform a new grid test. However, I need more samples for each setting in order to address the time variation, which is too much closer to each other now. Since I removed the channel buffer, I only have two parameters: the read buffer size (READ_BUFFER_SIZE) and the number of workers (N_WORKERS).
After 15 runs for each configuration, with [READ_BUFFER_SIZE/N_WORKER] variations, the results are:
[1024/025] Median:2.219864 Min:2.176016 Max:2.250926 Average:2.218512
[1024/045] Median:2.232022 Min:2.219185 Max:2.254537 Average:2.232696
[1024/050] Median:2.230360 Min:2.224120 Max:2.252666 Average:2.232072
[1024/055] Median:2.231307 Min:2.211719 Max:2.257619 Average:2.232077
[1024/075] Median:2.184521 Min:2.172680 Max:2.202394 Average:2.184986
[1024/100] Median:2.114413 Min:2.098569 Max:2.126056 Average:2.114260
[2048/025] Median:2.112397 Min:2.082739 Max:2.127026 Average:2.109444
[2048/045] Median:2.080504 Min:2.052388 Max:2.101977 Average:2.077760
[2048/050] Median:2.060059 Min:2.043855 Max:2.081475 Average:2.063090
[2048/055] Median:2.052428 Min:2.036254 Max:2.064517 Average:2.051182
[2048/075] Median:2.006269 Min:1.987433 Max:2.037105 Average:2.008363
[2048/100] Median:2.012136 Min:1.998069 Max:2.033619 Average:2.012824
[2500/025] Median:2.085206 Min:2.051325 Max:2.149669 Average:2.088950
[2500/045] Median:2.052305 Min:2.042962 Max:2.065635 Average:2.052392
[2500/050] Median:2.042339 Min:2.023924 Max:2.064953 Average:2.043449
[2500/055] Median:2.042570 Min:2.033146 Max:2.058255 Average:2.043690
[2500/075] Median:2.030126 Min:2.021994 Max:2.059866 Average:2.033594
[2500/100] Median:2.033681 Min:2.019922 Max:2.052254 Average:2.035110
[3000/025] Median:2.124746 Min:2.082351 Max:2.138877 Average:2.118401
[3000/045] Median:2.065936 Min:2.038780 Max:2.082305 Average:2.059880
[3000/050] Median:2.053482 Min:2.036321 Max:2.073193 Average:2.052350
[3000/055] Median:2.058694 Min:2.039742 Max:2.071381 Average:2.055151
[3000/075] Median:2.044610 Min:2.031621 Max:2.072240 Average:2.046833
[3000/100] Median:2.051081 Min:2.041319 Max:2.070420 Average:2.053736
[3500/025] Median:2.115581 Min:2.085326 Max:2.142923 Average:2.111501
[3500/045] Median:2.062000 Min:2.050305 Max:2.079701 Average:2.061979
[3500/050] Median:2.057308 Min:2.047556 Max:2.071838 Average:2.058065
[3500/055] Median:2.058585 Min:2.047697 Max:2.072047 Average:2.058442
[3500/075] Median:2.060888 Min:2.051787 Max:2.070400 Average:2.060377
[3500/100] Median:2.067534 Min:2.056189 Max:2.081957 Average:2.068087
[4096/025] Median:2.101917 Min:2.078075 Max:2.139795 Average:2.104907
[4096/045] Median:2.071588 Min:2.053040 Max:2.078682 Average:2.068556
[4096/050] Median:2.065348 Min:2.055219 Max:2.108920 Average:2.069129
[4096/055] Median:2.062510 Min:2.056066 Max:2.077945 Average:2.064237
[4096/075] Median:2.076443 Min:2.067886 Max:2.111381 Average:2.080161
[4096/100] Median:2.090874 Min:2.078334 Max:2.160026 Average:2.095570As you can see, READ_BUFFER_SIZE = 2048 * 2048 and N_WORKERS = 75, could even achieve less than 2 seconds in some runs.
Now using the winner configuration for the final test, I increased the number of runs to 55, and closed everything in computer but the terminal. The results are:
- Median: 1.969090
- Average: 1.968661
- Min: 1.956285
- Max: 1.985953
| Optimization | Time (in seconds) |
|---|---|
| Single Thread | 95.000000 |
| Goroutines | 8.327305 |
| Custom Byte Split | 5.526411 |
| Custom Byte Hash | 4.237007 |
| Parsing Float | 3.079632 |
| Custom Scan | 2.825991 |
| Custom Hash | 2.717442 |
| Swiss Map | 2.677549 |
| DJB2 Hash | 2.588396 |
| No Name and Temp Buffers | 2.070337 |
| Grid Test | 1.969090 |
Final Thoughts
Participating in the 1 Billion Row Challenge was really interesting for me, I didn’t expected to achieved such good results since I have low to no experience in such optimizations. Moreover, for me the results are more incredible because I didn’t bothered too much about manipulating the bytes individually, like the best Java solutions.
The last version of the code is presented below:
package main
import (
"fmt"
"io"
"os"
"r2p/utils"
"slices"
"sort"
"sync"
"github.com/dolthub/swiss"
)
const READ_BUFFER_SIZE = 2048 * 2048
const N_WORKERS = 75
type TrashItem struct {
Idx int
Value []byte
Initial bool
}
type StationData struct {
Name string
Min int
Max int
Sum int
Count int
}
var lock = &sync.Mutex{}
var lockIdx = 0
func trashBin(input chan *TrashItem, output chan *swiss.Map[uint64, *StationData], wg *sync.WaitGroup) {
defer wg.Done()
data := swiss.NewMap[uint64, *StationData](1024)
can := []*TrashItem{}
buffer := make([]byte, 1024)
for item := range input {
can = append(can, item)
can = saveCan(can, data, buffer)
}
output <- data
}
func saveCan(can []*TrashItem, data *swiss.Map[uint64, *StationData], buffer []byte) []*TrashItem {
for i, ref := range can {
if ref.Idx == 0 {
_, nameInit, nameEnd, tempInit, tempEnd := nextLine(0, ref.Value)
processLine(ref.Value[nameInit:nameEnd], ref.Value[tempInit:tempEnd], data)
return slices.Delete(can, i, i+1)
}
for j, oth := range can {
if ref.Idx == oth.Idx && i != j {
if ref.Initial {
copy(buffer[:len(ref.Value)], ref.Value)
copy(buffer[len(ref.Value):], oth.Value)
} else {
copy(buffer[:len(oth.Value)], oth.Value)
copy(buffer[len(oth.Value):], ref.Value)
}
total := len(ref.Value) + len(oth.Value)
end, nameInit, nameEnd, tempInit, tempEnd := nextLine(0, buffer)
processLine(buffer[nameInit:nameEnd], buffer[tempInit:tempEnd], data)
if end < total {
_, nameInit, nameEnd, tempInit, tempEnd := nextLine(end, buffer)
processLine(buffer[nameInit:nameEnd], buffer[tempInit:tempEnd], data)
}
if i > j {
can = slices.Delete(can, i, i+1)
can = slices.Delete(can, j, j+1)
} else {
can = slices.Delete(can, j, j+1)
can = slices.Delete(can, i, i+1)
}
return can
}
}
}
return can
}
func consumer(file *os.File, trash chan *TrashItem, output chan *swiss.Map[uint64, *StationData], wg *sync.WaitGroup) {
defer wg.Done()
data := swiss.NewMap[uint64, *StationData](1024)
readBuffer := make([]byte, READ_BUFFER_SIZE)
for {
lock.Lock()
lockIdx++
idx := lockIdx
n, err := file.Read(readBuffer)
lock.Unlock()
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
// ignoring first line
start := 0
for i := 0; i < n; i++ {
if readBuffer[i] == 10 {
start = i + 1
break
}
}
trash <- &TrashItem{idx - 1, readBuffer[:start], false}
// ignoring last line
final := 0
for i := n - 1; i >= 0; i-- {
if readBuffer[i] == 10 {
final = i
break
}
}
trash <- &TrashItem{idx, readBuffer[final+1 : n], true}
readingIndex := start
for readingIndex < final {
next, nameInit, nameEnd, tempInit, tempEnd := nextLine(readingIndex, readBuffer)
readingIndex = next
processLine(readBuffer[nameInit:nameEnd], readBuffer[tempInit:tempEnd], data)
}
}
output <- data
}
func nextLine(readingIndex int, reading []byte) (nexReadingIndex, nameInit, nameEnd, tempInit, tempEnd int) {
i := readingIndex
nameInit = readingIndex
for reading[i] != 59 { // ;
i++
}
nameEnd = i
i++ // skip ;
tempInit = i
for i < len(reading) && reading[i] != 10 { // \n
i++
}
tempEnd = i
readingIndex = i + 1
return readingIndex, nameInit, nameEnd, tempInit, tempEnd
}
func processLine(name, temperature []byte, data *swiss.Map[uint64, *StationData]) {
temp := bytesToInt(temperature)
id := hash(name)
station, ok := data.Get(id)
if !ok {
data.Put(id, &StationData{string(name), temp, temp, temp, 1})
} else {
if temp < station.Min {
station.Min = temp
}
if temp > station.Max {
station.Max = temp
}
station.Sum += temp
station.Count++
}
}
func run() {
outputChannels := make([]chan *swiss.Map[uint64, *StationData], N_WORKERS+1)
// Read file
file, err := os.Open("measurements.txt")
if err != nil {
panic(err)
}
defer file.Close()
var wg sync.WaitGroup
var wgTrash sync.WaitGroup
wg.Add(N_WORKERS)
wgTrash.Add(1)
trash := make(chan *TrashItem, N_WORKERS*2)
output := make(chan *swiss.Map[uint64, *StationData], 1)
go trashBin(trash, output, &wgTrash)
outputChannels[0] = output
for i := 0; i < N_WORKERS; i++ {
output := make(chan *swiss.Map[uint64, *StationData], 1)
go consumer(file, trash, output, &wg)
outputChannels[i+1] = output
}
wg.Wait()
close(trash)
wgTrash.Wait()
for i := 0; i < N_WORKERS+1; i++ {
close(outputChannels[i])
}
data := swiss.NewMap[uint64, *StationData](1000)
for i := 0; i < N_WORKERS+1; i++ {
m := <-outputChannels[i]
m.Iter(func(station uint64, stationData *StationData) bool {
v, ok := data.Get(station)
if !ok {
data.Put(station, stationData)
} else {
if stationData.Min < v.Min {
v.Min = stationData.Min
}
if stationData.Max > v.Max {
v.Max = stationData.Max
}
v.Sum += stationData.Sum
v.Count += stationData.Count
}
return false
})
}
printResult(data)
}
func hash(name []byte) uint64 {
var h uint64 = 5381
for _, b := range name {
h = (h << 5) + h + uint64(b)
}
return h
}
func printResult(data *swiss.Map[uint64, *StationData]) {
result := make(map[string]*StationData, data.Count())
keys := make([]string, 0, data.Count())
data.Iter(func(k uint64, v *StationData) (stop bool) {
keys = append(keys, v.Name)
result[v.Name] = v
return false
})
sort.Strings(keys)
print("{")
for _, k := range keys {
v := result[k]
fmt.Printf("%s=%.1f/%.1f/%.1f, ", k, float64(v.Min)/10, (float64(v.Sum)/10)/float64(v.Count), float64(v.Max)/10)
}
print("}\n")
}
func bytesToInt(byteArray []byte) int {
var result int
negative := false
for _, b := range byteArray {
if b == 46 { // .
continue
}
if b == 45 { // -
negative = true
continue
}
result = result*10 + int(b-48)
}
if negative {
return -result
}
return result
}
func main() {
f, err := os.Create("cpu_profile.prof")
if err != nil {
panic(err)
}
defer f.Close()
if err := pprof.StartCPUProfile(f); err != nil {
panic(err)
}
defer pprof.StopCPUProfile()
started := time.Now()
run()
fmt.Printf("%0.6f\n", time.Since(started).Seconds())
}